

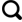


0 引言
受海洋因素和大气因素的影响,海冰变化机制异常复杂,预测极富挑战性。目前海冰预测主要有三种方法:统计预测方法、模式预测方法和近年来兴起的机器学习方法。统计方法主要是基于历史数据建立海冰变量随时间或特征量变化的统计模型,对未来的海冰范围进行预测。如Schröder等[7]选取了海冰表面融池作为预测特征,通过回归分析发现融池可作为9月海冰最小范围的良好预测指标。统计方法的优点在于运算简单,缺点是无法把握特征与预测目标之间的非线性关系。模式预测方法是在模式动力框架、初始和边界条件的约束下,充分考虑影响海冰变化的热动力过程和机制的基础上开展预测。Wayand等[8]发现不同海冰模式之间的预测结果差异较大,但是通过多模式集合平均方法可提升预测技能。模式预测的优点在于其预测结果的可解释性较强,缺点在于针对海冰变化过程和机理的参数化方案尚不完善,为预测结果带来较大不确定性,且对计算机算力的要求较高[9]。相较而言,机器学习可较好地把握特征与变量之间的非线性关系,快速获得预测结果,且消耗算力较小,应用前景广泛[10],但缺点是对预测结果的可解释性较差。
本文将基于不同机器学习方法开展北极海冰密集度和范围预测。受计算能力的限制,本文开展了月尺度预测。Kim等[11]选取喀拉海和巴伦支海作为研究区域,对比了深度神经网络和多元回归算法对海冰密集度的预测效果,指出前者具有明显优势。Chi等[12]对比了多层感知机(MLP),长短时记忆神经网络(LSTM),和自回归模型(autoregressive model)在海冰密集度上的预测效果,发现LSTM精度最高,均方根误差仅为8.89%。总体而言,现阶段运用机器学习方法开展的海冰预测研究较为初步,特别缺乏对不同机器学习算法在海冰预测效果方面的全面评价。本文对比分析了支持向量机(SVR)、深度森林(DF)、LGB、XGB和CAT等5种机器学习算法和贝叶斯回归、岭回归、套索回归和深度森林作为元模型、LGB、XGB和CAT作为基模型的等4种堆叠式集成学习模型,以及深度神经网络(DNN)、卷积神经网络(CNN)、时空卷积网络(ConvLSTM)3种深度学习模型对北极海冰密集度和范围的预测效果,给出了未来开展月尺度北极海冰预测的优势模型建议。
1 数据与方法
1.1 数据
本文使用的海冰密集度数据为美国冰雪数据中心(NSIDC)提供的被动微波海冰密集度气候数据记录(Climate Data Record of Passive Microwave Sea Ice Concentration),简称NSIDC海冰数据集(
海冰冰龄数据采用NSIDC发布的EASE-Grid Sea Ice Age (Version 4)(
气温、降水、气压、风速、辐射、热通量采用ERA5再分析数据(
影响海冰变化的特征主要包括:海冰自身物理特性,以及影响海冰冻融过程的热力因素和动力因素。物理特性主要包括冰龄、皮温和反照率等[19]。以反照率为例,主要受海冰表面形态和上覆积雪特征的影响,可用于表征海冰当前的冻融状态和吸热效率[7]。热力影响因素方面,近年来有研究表明,降水相态变化和降雨首日是指示消融期海冰退缩速率的重要前兆信号[20]。除海表温度和气温外,感热潜热通量和净辐射通量也是影响海冰能量平衡的重要因素。此外,大气环流的变化会对大尺度海冰动力输送产生影响。本文选取10 m风速和海表气压作为决定海冰冻融过程的主要动力特征参量。除上述因素外,大气和海洋向极热输送,陆面入海径流,冰-海耦合过程,上升流等也是促进海冰消融的重要因素[21-22],但由于缺乏上述变量相关的大尺度观测资料,目前尚无法将这些因素全部考虑在内。本文所使用的海冰预测特征库详见表1。
表1 海冰预测参量特征库
Table 1
| 变量名 | 数据源 | 时间分辨率 | 空间分辨率 | 单位 |
|---|---|---|---|---|
| 海冰密集度 | NSIDC | 日均/月均 | 25 km | % |
| 上月海冰密集度 | NSIDC | 日均/月均 | 25 km | % |
| 上年海冰密集度 | NSIDC | 日均/月均 | 25 km | % |
| 海冰冰龄 | NSIDC | 周均/月均 | 12.5 km | a |
| 海表温度 | ERA5 | 月均 | 0.25° | K |
| 海表气压 | ERA5 | 月均 | 0.25° | Pa |
| 10 m经纬风速 | ERA5 | 月均 | 0.25° | m·s-1 |
| 总云覆盖 | ERA5 | 月均 | 0.25° | % |
| 长/短波辐射通量 | ERA5 | 月均 | 0.25° | W·m-2 |
| 感/潜热通量 | ERA5 | 月均 | 0.25° | W·m-2 |
| 2 m气温 | ERA5 | 月均 | 0.25° | K |
| 预报反照率 | ERA5 | 月均 | 0.25° | % |
| 海冰温度 | ERA5 | 月均 | 0.25° | K |
| 总降水 | ERA5 | 月均 | 0.25° | mm·d-1 |
| 降雪 | ERA5 | 月均 | 0.25° | mm·d-1 |
1.2 方法
机器学习方法可分为传统的机器学习和深度学习两大类,集成学习是机器学习的一种组合式优化方法,主要通过构建组合多个学习器的方式完成数据学习。集成学习用给定的数据样本训练一组基学习器,用不同的模型融合策略组合基学习器得到增强模型,其往往比单个学习器具有更好的预测精度和泛化性能[23]。集成学习算法主要有三大类:Boosting(提升式)类,Bagging(装袋式)类和stacking(堆叠式)类。Boosting 类集成学习算法是指通过将相似度较高的模型进行串联的算法(如GBDT, Adaboost, XGBoost, LightGBM, CatBoost);而个体学习器之间不存在强依赖关系进行并联的被称为Bagging类算法(如随机森林)。最后一类是stacking模型,其基本思想是将前一层模型的预测结果作为后层模型的训练集,后层模型拟合预测结果和真实值之间的关系,相当于把不同类型学习器进行串并联组合,得到更好的预测结果。
本文将全面对比不同机器学习方法在北极海冰预测中的效果,选择线性回归模型作为参照模型。机器学习算法选择SVR(Support Vector Regression)、决策树算法、LGB算法、XGB算法和CAT算法。LGB、CAT和XGB三类Boosting类集成学习算法的特点和差异如表2所示。
表2 树模型类机器学习方法对比
Table 2
| 算法 | 数据处理 | 节点分割策略 | 树生长策略 |
|---|---|---|---|
| LGB | GOES(单边梯度抽样算法)+列采样 | 直方图算法EFB(互斥特征捆绑) | Leaf-wise(先生成增益最大的子节点) |
| CAT | 类别特征自动处理 | 无偏梯度分裂 | 对称树(镜像二叉树) |
| XGB | 列采样 | 精确贪心+近似算法 | Level-wise(逐层生成子节点) |
深度学习算法特指网络结构大于两层的神经网络算法,例如CNN、RNN、LSTM和ConvLSTM等模型,各模型特点对比如表3所示。其中,适用于时空序列预测的模型有DNN、CNN和ConvLSTM三种。
表3 深度学习模型对比
Table 3
| 模型名称 | 基本结构 | 特点 |
|---|---|---|
| CNN | 卷积层+池化层+全连接层 | 参数共享、捕捉数据细节 |
| RNN | NN+时间层 | 处理时间序列,存在梯度爆炸 |
| LSTM | 门控单元(遗忘,输出,更新) | 通过门控单元解决梯度爆炸问题 |
| ConvLSTM | 卷积层+LSTM | 更好处理数据的时空相关性 |
在基于stacking集成学习思想的创新模型中,效果较好的是深度森林。深度森林是基于集成学习的思想,以树模型作为基础模型,参考神经网络的结构创新而得的一种新的机器学习算法[24-25]。其结构特点为鲜明的层联结构:将神经网络中的每一个神经元节点替换成了树模型,通过每层的训练处理自动提取特征,层层堆叠集成增加模型复杂度减少误差;其数据处理特点为多粒度扫描,即类比CNN卷积的方法,使用不同大小的滑窗对原始特征进行池化平均(pooling)操作,然后再输出决策树层中训练。深度森林的优势首先在于无需调参,深度森林每新增一层就会自动验证精度,当精度不再提升会自动停止增加层数,结束训练;其次在于该模型通过数据的差异性采样和模型的集成处理能够更好地防止过拟合。本文拟采用第一层为LightGBM、CatBoost和XGBoost的基模型,第二层为使用增加L1正则化损失函数的贝叶斯回归、岭回归、Lasso回归和深度森林作为元模型的4种stacking集成学习作为对比,其模型名分别简称为Bayeslr_stacking、Ridge_stacking、Lasso_stacking和DF_stacking。
本文拟选取1989—1999年共计10年的海冰预测参量特征库数据作为训练集,以北极海冰开始显著退缩的过渡年份(2000年)的数据作为验证集。数据集的特征X为T-1月的海冰预测参量特征(表1中15个变量),预测目标y为T月的海冰密集度,通过对训练集的学习,模型拟合前一个月特征变量和本月海冰密集度之间的关系,进行提前一个月的海冰密集度预测。在控制训练数据相同的条件下,对比线性回归、SVR、LightGBM、CatBoost和XGBoost以及深度森林和stacking集成学习模型,DNN、CNN和ConvLSTM三种深度学习模型在海冰预测上的效果。海冰预测的目标量是海冰密集度,是回归问题,故采用MAE[平均绝对误差,预测值与真实值绝对偏差的均值,其计算方法如
式中:
海冰范围根据密集度空间数据进行计算,首先筛选出密集度大于15%的格点,然后将这些格点对应面积相加即得到海冰范围值的大小。
2 结果与分析
在控制训练使用数据量相同的前提下,经过3次重复训练,最终在测试集上的结果取平均值,从精度评价指标和可视化结果两方面对基于不同算法的海冰预测效果进行对比和评价。
2.1 预测精度对比
图1
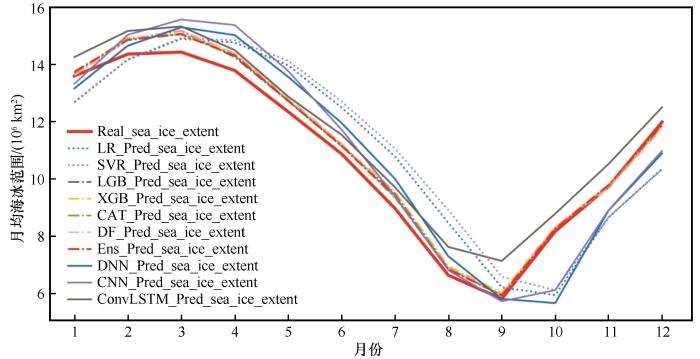
图1
各模型给出的2000年逐月海冰范围预测结果
Fig.1
Predicted monthly sea ice extents in 2000 by various models
表4 各模型给出的2000年海冰范围预测精度 (×106 km2)
Table 4
| 模型名 | RMSE | MAE |
|---|---|---|
| LR | 1.50 | 1.35 |
| SVR | 1.38 | 1.23 |
| LGB | 0.37 | 0.31 |
| XGB | 0.39 | 0.33 |
| CAT | 0.36 | 0.30 |
| DF | 0.52 | 0.46 |
| Ens | 0.35 | 0.29 |
| DNN | 1.22 | 1.03 |
| CNN | 1.05 | 0.88 |
| ConvLSTM | 0.80 | 0.77 |
图2
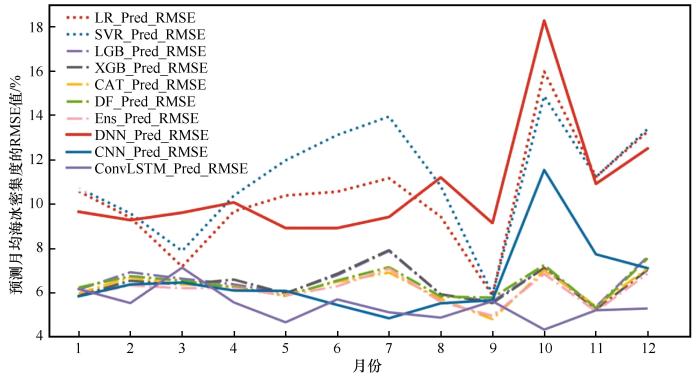
图2
各模型对2000年逐月海冰密集度的预测偏差(RMSE)
Fig. 2
RMSE of monthly sea ice concentrations in 2000 predicted by various models
表5 不同模型预测的2000年逐月海冰密集度偏差(以RMSE和R2表示)
Table 5
| 模型名 | 逐月RMSE平均值/% | 逐月R2平均值 |
|---|---|---|
| LR | 10.39 | 0.91 |
| SVR | 11.14 | 0.90 |
| LGB | 6.53 | 0.96 |
| XGB | 6.41 | 0.97 |
| CAT | 6.22 | 0.97 |
| DF | 7.07 | 0.95 |
| Ens | 6.12 | 0.97 |
| DNN | 10.65 | 0.90 |
| CNN | 6.56 | 0.94 |
| ConvLSTM | 5.79 | 0.97 |
2.2 海冰预测可视化结果
2.2.1 机器学习可视化结果
同遥感观测相比,各种算法都可以较好地刻画海冰的空间分布。但在海冰边缘区域存在较为明显的预测偏差。结合差值图可以看出,在2000年9月的海冰密集度预测结果中,不同算法预测偏差存在较大的空间差异。三种树模型偏差在空间分布上较为类似,均在北冰洋中心区域存在低估,而在东西伯利亚海偏北地区存在高估(图3)。总体而言,深度森林(DF)、LightGBM (LGB)、XGBoost (XGB)和CatBoost (CAT)四种模型的预测结果与观测更为接近,其在9月的RMSE值分别为5.82%、5.61%、5.53%和4.99%,而LR和SVR的RMSE值分别是6.13%和6.07%。
图3
图3
不同机器学习模型预测的2000年9月海冰密集度偏差
Fig. 3
The bias of sea ice concentration between different machine learning models predicted and remote sensing observed in September, 2000
2.2.2 集成学习可视化结果
不同堆叠式(stacking)集成学习的预测结果非常类似。以2000年3月为例,4种堆叠模型的偏差结果高度一致(图4)。从3月RMSE值量化来看,Bayeslr_stacking为6.21%,Ridge_stacking为6.20%,Lasso_stacking为6.17%,DF_stacking为6.22%,故Lasso堆叠集成模型的预测效果最优,而深度森林堆叠模型的预测效果稍差,故选取Lasso堆叠集成模型作为Ens集成学习模型在表4和表5中进行统计。从表5一整年逐月RMSE均值来看,堆叠模型值为6.12%,LGB为6.53%,XGB为6.41%,CAT为6.22%,同三种表现较优的机器学习的结果相比,堆叠集成学习模型(Ens)的预测精度更高,在海冰密集度预测精度上有约1%~4%的提升。
图4

图4
不同堆叠式集成学习模型预测的2000年3月海冰密集度偏差
Fig. 4
The bias of sea ice concentration between different stacking ensemble learning models predicted and remote sensing observed in March, 2000
2.2.3 深度学习可视化结果
由图5可知,各类深度学习模型都能很好地刻画2000年3月和9月海冰冰情的空间分布情况。预测偏差方面,深度神经网络在3月和9月有着相似的误差分布,均是在北冰洋及周边海域出现了海冰密集度的低估情况,而在较低纬度海域有所高估。而CNN和ConvLSTM预测误差的分布区域类似,但是高低估情况相反。在2000年3月的预测结果中,CNN在大西洋一侧存在低估,在鄂霍次克海存在高估,而ConvLSTM在上述区域有着相反的高低估情况。而在9月,ConvLSTM低估了边缘区域海冰密集度,而CNN却明显高估了这些区域的海冰密集度,但ConvLSTM在低估区域面积和偏差上都小于CNN的结果。从RMSE的结果量化来看,9月CNN为5.67%,ConvLSTM为5.51%,故ConvLSTM预测结果较优(图5)。
图5
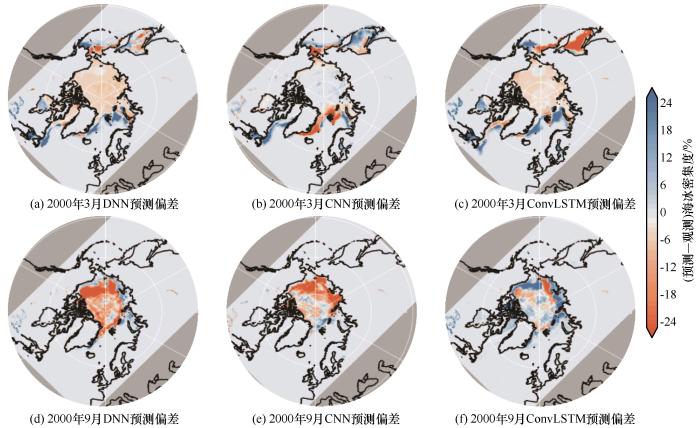
图5
不同深度学习模型预测的2000年3月、9月海冰密集度偏差
Fig. 5
The prediction bias of sea ice concentration from different deep learning models relative to remote sensing observations in March and September, 2000
3 结论与展望
本文基于遥感和再分析数据,开展了超前一个月的北极海冰冰情预测,对12种不同机器学习算法在海冰密集度和海冰范围上的预测效果进行了对比分析。结果显示在对海冰密集度的预测中,ConvLSTM表现最优,套索堆叠集成学习模型预测效果次之;在海冰范围预测中,堆叠式集成学习模型的预测表现最好。此外,集成学习是提升机器学习预测效果的有效方法。基于stacking方法的集成学习模型相较于三种单一树模型(LGB、XGB和CAT)在海冰密集度预测效果上有约1%~4%的提升。
在实际应用中,除了超前一个月的预测需求外,对更长预测时效(如跨季节尺度预测)也有较大需求,未来需针对不同预测时效,对模型预测效果进行深入对比分析,以便为特定预测时效匹配最优模型。同时在现有工作的基础上,结合海冰预测实际及其变化机制研究进展,对现有的机器学习模型进行结构创新,如增加物理机制约束,尝试更多集成学习模型结构,得到实际应用中预测效果更好的机器学习模型。此外,有必要对机器学习模型的解释方法进行研究,探索通用的模型解释方法对不同模型进行分析,将机器学习海冰预测中的“黑箱”变为“灰箱”。
参考文献
The emergence of surface-based Arctic amplification
[J].
The Arctic amplification debate
[J].
Observationally-constrained projections of an ice-free Arctic even under a low emission scenario
[J].
Risk assessment of ship navigation in the northwest passage: historical and projection
[J].
The predictability, irreversibility and deep uncertainty of cryospheric change
[J].
冰冻圈变化的可预测性、不可逆性和深度不确定性
[J].
Interpretation of IPCC SROCC on polar system changes and their impacts and adaptations
[J].
极地系统变化及其影响与适应新认识
[J].
September Arctic sea-ice minimum predicted by spring melt-pond fraction
[J].
A year-round subseasonal-to-seasonal sea ice prediction portal
[J].
Application of deep learning method in Arctic sea ice prediction
[J].
深度学习方法在北极海冰预报中的应用
[J].
Deep learning and process understanding for data-driven Earth system science
[J].
Satellite-based prediction of Arctic sea ice concentration using a deep neural network with multi-model ensemble
[J].
Prediction of arctic sea ice concentration using a fully data driven deep neural network
[J].
Determination of sea ice parameters with the NIMBUS 7 SMMR
[J].
Characteristics of Arctic winter sea ice from satellite multispectral microwave observations
[J].
The ERA5 global reanalysis
[J].
The ERA-Interim reanalysis: configuration and performance of the data assimilation system
[J].
Improved performance of ERA5 in Arctic gateway relative to four global atmospheric reanalyses
[J].
Evaluation of seven different atmospheric reanalysis products in the Arctic
[J].
Arctic sea ice thickness, volume, and multiyear ice coverage: losses and coupled variability (1958—2018)
[J].
A key factor initiating surface ablation of Arctic sea ice: earlier and increasing liquid precipitation
[J].
Upwelling of Atlantic Water in Barrow Canyon, Chukchi Sea
[J].
Research progress for the changes of Arctic Ocean surface wave with diminishing sea ice
[J].
海冰覆盖度变化下北冰洋海浪研究进展
[J].
Machine learning enhancement of storm-scale ensemble probabilistic quantitative precipitation forecasts
[J].
Multi-layered gradient boosting decision trees
[J].

 甘公网安备 62010202000676号
甘公网安备 62010202000676号
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}