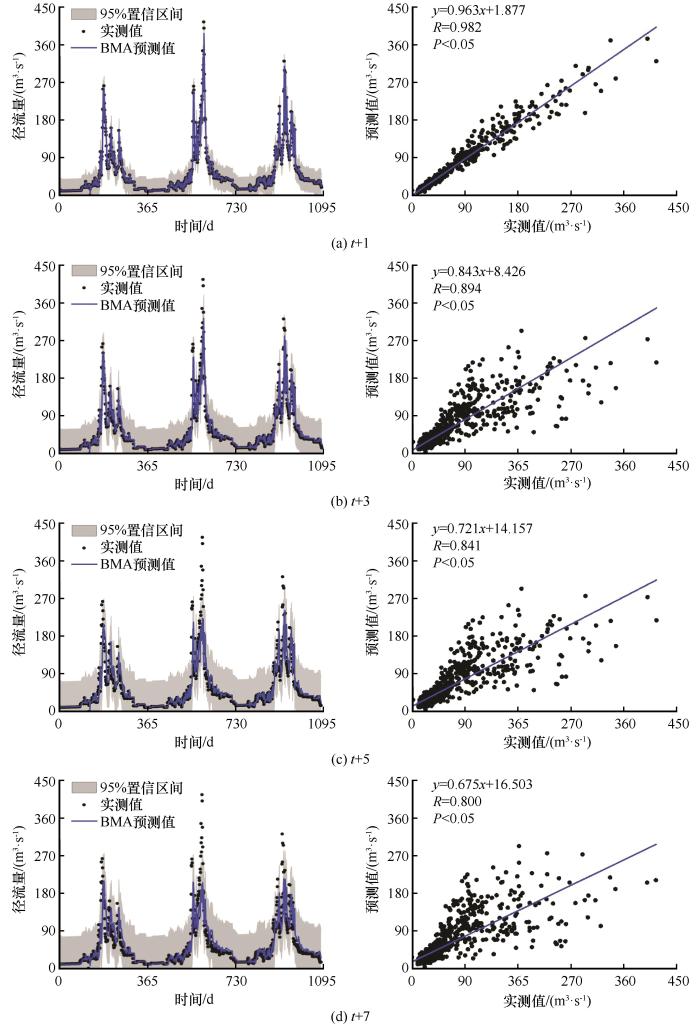
Accurate and reliable runoff prediction is of great significance for the scientific management and planning of water resources, especially in the arid and semi-arid areas where water resources are scarce. Runoff prediction has important practical significance for the efficient utilization of water resources and the economic operation of water conservation projects.In view of the problem that it is difficult to make use of the advantages of each prediction model because a single method is usually used for modeling and prediction of runoff prediction. In this paper, the Extreme Learning Machine (ELM) model, Support Vector Machine (SVM) model and Multivariate Adaptive Regression Spline (MARS) model were used to develop the runoff prediction model in the upper reaches of Shule River in 1 to 7 day. On this basis, the Bayesian Model Average (BMA) method was also used to combine the prediction results of ELM, SVM and MARS models, and a combined runoff prediction model was constructed to obtain more reliable predictions. The 95% confidence interval of BMA was obtained by Monte Carlo sampling method, and the uncertainty of the predictions was analyzed. The results show that ELM, SVM, MARS model and BMA combination model are suitable for medium and long term daily runoff prediction in arid and semi-arid areas; BMA has higher prediction accuracy than the single models and can provide more reliable and accurate predictions; The 95% confidence interval of BMA has high coverage of measured values, and can provide better deterministic and probabilistic predictions. The results suggest that BMA has better prediction performance than the single models under the condition of limited data, and can be an effective method for medium and long-term daily runoff prediction in arid and semi-arid areas.
Keywords:daily runoff
;
machine learning
;
Bayesian Model Average
;
uncertainty analysis
;
Shule River
ZHOU Ting, WEN Xiaohu, FENG Qi, YIN Zhenliang, YANG Linshan. Study on runoff prediction of Shule River based on BMA multi-model combination[J]. Journal of Glaciology and Geocryology, 2022, 44(5): 1606-1619 doi:10.7522/j.issn.1000-0240.2022.0141
针对径流预测研究通常采用单一方法进行建模与预测,难以有效利用各预测模型优势的问题,有学者提出多模型融合的方法,即将多个单一模型进行组合,通过降低单一模型的偏差,发挥各模型的优势,使预测值更加接近于实测值,进而提高径流预测结果的精确度与可靠性[13]。Zhang等[14]运用奇异谱分析(SSA)与自回归综合移动平均模型(ARIMA)结合对年径流量进行预测。结果表明组合模型具有更佳的预测能力。Wang等[15]将人工神经网络模型(ANN)与集成经验模式分解(EEMD)结合用于中长期径流时间序列预测,其结果较单一ANN模型有了明显的改进。Shamseldin等[16]运用简单平均法(SAM)、加权平均法(WAM)、神经网络方法(NNM)对5个水文模型进行组合用于日径流量预测,结果表明三组组合模型的预测精度均高于单一模型。以上方法均基于确定性的理论,集成不同模型的预测结果,能够提供更精确的综合预测结果,但无法定量评价模型结构的不确定性[12]。基于贝叶斯理论发展起来的贝叶斯模型平均方法(Bayesian Model Averaging,BMA)通过计算单一模型的后验概率,并基于后验概率对组合模型成员进行加权平均,判断成员模型优劣。因此,BMA可以有效处理组合模型成员的不确定性,在提供精度更高的预测结果的同时,还能提供可靠的预测概率,定量评价模型结构不确定性对预测结果的影响[17]。近年来,BMA方法也被应用于水文学领域,董磊华等[18]运用BMA方法综合SIMHYD、SMAR(Soil Moisture Accounting and Routing),以及新安江模型的预报结果,推求出可靠的预报值的概率分布;Jiang等[19]利用BMA方法集成多卫星降水产品,对湘江日径流进行模拟;Xu等[20]以中国为研究区,研究了BMA在多模态水文预报后处理中的应用。以上研究均表明BMA能够提高水文预测的准确性与可靠性,还能得到更为优良的预测区间。然而,目前运用BMA方法进行中长期日径流预测的相关研究尚不多见。
Improvement and application of GIS-based distributed SWAT hydrological modeling on high altitude, cold, semi-arid catchment of Heihe River Basin, China
A comparative study of artificial neural network, adaptive neuro fuzzy inference system and support vector machine for forecasting river flow in the semiarid mountain region
Comprehensive evaluation of multi-satellite precipitation products with a dense rain gauge network and optimally merging their simulated hydrological flows using the Bayesian model averaging method
[J]. Journal of Hydrology, 2012, 452/453: 213-225.
Variation of water cycle factors in the western Qilian Mountain area under climate warming:taking the mountain watershed of the main stream of Shule River Basin for example
[J]. Journal of Mountain Science, 2012, 30(6): 675-680.
Improvement and application of GIS-based distributed SWAT hydrological modeling on high altitude, cold, semi-arid catchment of Heihe River Basin, China
A comparative study of artificial neural network, adaptive neuro fuzzy inference system and support vector machine for forecasting river flow in the semiarid mountain region
... 针对径流预测研究通常采用单一方法进行建模与预测,难以有效利用各预测模型优势的问题,有学者提出多模型融合的方法,即将多个单一模型进行组合,通过降低单一模型的偏差,发挥各模型的优势,使预测值更加接近于实测值,进而提高径流预测结果的精确度与可靠性[13].Zhang等[14]运用奇异谱分析(SSA)与自回归综合移动平均模型(ARIMA)结合对年径流量进行预测.结果表明组合模型具有更佳的预测能力.Wang等[15]将人工神经网络模型(ANN)与集成经验模式分解(EEMD)结合用于中长期径流时间序列预测,其结果较单一ANN模型有了明显的改进.Shamseldin等[16]运用简单平均法(SAM)、加权平均法(WAM)、神经网络方法(NNM)对5个水文模型进行组合用于日径流量预测,结果表明三组组合模型的预测精度均高于单一模型.以上方法均基于确定性的理论,集成不同模型的预测结果,能够提供更精确的综合预测结果,但无法定量评价模型结构的不确定性[12].基于贝叶斯理论发展起来的贝叶斯模型平均方法(Bayesian Model Averaging,BMA)通过计算单一模型的后验概率,并基于后验概率对组合模型成员进行加权平均,判断成员模型优劣.因此,BMA可以有效处理组合模型成员的不确定性,在提供精度更高的预测结果的同时,还能提供可靠的预测概率,定量评价模型结构不确定性对预测结果的影响[17].近年来,BMA方法也被应用于水文学领域,董磊华等[18]运用BMA方法综合SIMHYD、SMAR(Soil Moisture Accounting and Routing),以及新安江模型的预报结果,推求出可靠的预报值的概率分布;Jiang等[19]利用BMA方法集成多卫星降水产品,对湘江日径流进行模拟;Xu等[20]以中国为研究区,研究了BMA在多模态水文预报后处理中的应用.以上研究均表明BMA能够提高水文预测的准确性与可靠性,还能得到更为优良的预测区间.然而,目前运用BMA方法进行中长期日径流预测的相关研究尚不多见. ...
... 针对径流预测研究通常采用单一方法进行建模与预测,难以有效利用各预测模型优势的问题,有学者提出多模型融合的方法,即将多个单一模型进行组合,通过降低单一模型的偏差,发挥各模型的优势,使预测值更加接近于实测值,进而提高径流预测结果的精确度与可靠性[13].Zhang等[14]运用奇异谱分析(SSA)与自回归综合移动平均模型(ARIMA)结合对年径流量进行预测.结果表明组合模型具有更佳的预测能力.Wang等[15]将人工神经网络模型(ANN)与集成经验模式分解(EEMD)结合用于中长期径流时间序列预测,其结果较单一ANN模型有了明显的改进.Shamseldin等[16]运用简单平均法(SAM)、加权平均法(WAM)、神经网络方法(NNM)对5个水文模型进行组合用于日径流量预测,结果表明三组组合模型的预测精度均高于单一模型.以上方法均基于确定性的理论,集成不同模型的预测结果,能够提供更精确的综合预测结果,但无法定量评价模型结构的不确定性[12].基于贝叶斯理论发展起来的贝叶斯模型平均方法(Bayesian Model Averaging,BMA)通过计算单一模型的后验概率,并基于后验概率对组合模型成员进行加权平均,判断成员模型优劣.因此,BMA可以有效处理组合模型成员的不确定性,在提供精度更高的预测结果的同时,还能提供可靠的预测概率,定量评价模型结构不确定性对预测结果的影响[17].近年来,BMA方法也被应用于水文学领域,董磊华等[18]运用BMA方法综合SIMHYD、SMAR(Soil Moisture Accounting and Routing),以及新安江模型的预报结果,推求出可靠的预报值的概率分布;Jiang等[19]利用BMA方法集成多卫星降水产品,对湘江日径流进行模拟;Xu等[20]以中国为研究区,研究了BMA在多模态水文预报后处理中的应用.以上研究均表明BMA能够提高水文预测的准确性与可靠性,还能得到更为优良的预测区间.然而,目前运用BMA方法进行中长期日径流预测的相关研究尚不多见. ...
Hydrological ensemble forecasting method based on stochastic combination of multiple models
1
2021
... 针对径流预测研究通常采用单一方法进行建模与预测,难以有效利用各预测模型优势的问题,有学者提出多模型融合的方法,即将多个单一模型进行组合,通过降低单一模型的偏差,发挥各模型的优势,使预测值更加接近于实测值,进而提高径流预测结果的精确度与可靠性[13].Zhang等[14]运用奇异谱分析(SSA)与自回归综合移动平均模型(ARIMA)结合对年径流量进行预测.结果表明组合模型具有更佳的预测能力.Wang等[15]将人工神经网络模型(ANN)与集成经验模式分解(EEMD)结合用于中长期径流时间序列预测,其结果较单一ANN模型有了明显的改进.Shamseldin等[16]运用简单平均法(SAM)、加权平均法(WAM)、神经网络方法(NNM)对5个水文模型进行组合用于日径流量预测,结果表明三组组合模型的预测精度均高于单一模型.以上方法均基于确定性的理论,集成不同模型的预测结果,能够提供更精确的综合预测结果,但无法定量评价模型结构的不确定性[12].基于贝叶斯理论发展起来的贝叶斯模型平均方法(Bayesian Model Averaging,BMA)通过计算单一模型的后验概率,并基于后验概率对组合模型成员进行加权平均,判断成员模型优劣.因此,BMA可以有效处理组合模型成员的不确定性,在提供精度更高的预测结果的同时,还能提供可靠的预测概率,定量评价模型结构不确定性对预测结果的影响[17].近年来,BMA方法也被应用于水文学领域,董磊华等[18]运用BMA方法综合SIMHYD、SMAR(Soil Moisture Accounting and Routing),以及新安江模型的预报结果,推求出可靠的预报值的概率分布;Jiang等[19]利用BMA方法集成多卫星降水产品,对湘江日径流进行模拟;Xu等[20]以中国为研究区,研究了BMA在多模态水文预报后处理中的应用.以上研究均表明BMA能够提高水文预测的准确性与可靠性,还能得到更为优良的预测区间.然而,目前运用BMA方法进行中长期日径流预测的相关研究尚不多见. ...
基于多模型随机组合的水文集合预报方法研究
1
2021
... 针对径流预测研究通常采用单一方法进行建模与预测,难以有效利用各预测模型优势的问题,有学者提出多模型融合的方法,即将多个单一模型进行组合,通过降低单一模型的偏差,发挥各模型的优势,使预测值更加接近于实测值,进而提高径流预测结果的精确度与可靠性[13].Zhang等[14]运用奇异谱分析(SSA)与自回归综合移动平均模型(ARIMA)结合对年径流量进行预测.结果表明组合模型具有更佳的预测能力.Wang等[15]将人工神经网络模型(ANN)与集成经验模式分解(EEMD)结合用于中长期径流时间序列预测,其结果较单一ANN模型有了明显的改进.Shamseldin等[16]运用简单平均法(SAM)、加权平均法(WAM)、神经网络方法(NNM)对5个水文模型进行组合用于日径流量预测,结果表明三组组合模型的预测精度均高于单一模型.以上方法均基于确定性的理论,集成不同模型的预测结果,能够提供更精确的综合预测结果,但无法定量评价模型结构的不确定性[12].基于贝叶斯理论发展起来的贝叶斯模型平均方法(Bayesian Model Averaging,BMA)通过计算单一模型的后验概率,并基于后验概率对组合模型成员进行加权平均,判断成员模型优劣.因此,BMA可以有效处理组合模型成员的不确定性,在提供精度更高的预测结果的同时,还能提供可靠的预测概率,定量评价模型结构不确定性对预测结果的影响[17].近年来,BMA方法也被应用于水文学领域,董磊华等[18]运用BMA方法综合SIMHYD、SMAR(Soil Moisture Accounting and Routing),以及新安江模型的预报结果,推求出可靠的预报值的概率分布;Jiang等[19]利用BMA方法集成多卫星降水产品,对湘江日径流进行模拟;Xu等[20]以中国为研究区,研究了BMA在多模态水文预报后处理中的应用.以上研究均表明BMA能够提高水文预测的准确性与可靠性,还能得到更为优良的预测区间.然而,目前运用BMA方法进行中长期日径流预测的相关研究尚不多见. ...
Singular spectrum analysis and ARIMA hybrid model for annual runoff forecasting
1
2011
... 针对径流预测研究通常采用单一方法进行建模与预测,难以有效利用各预测模型优势的问题,有学者提出多模型融合的方法,即将多个单一模型进行组合,通过降低单一模型的偏差,发挥各模型的优势,使预测值更加接近于实测值,进而提高径流预测结果的精确度与可靠性[13].Zhang等[14]运用奇异谱分析(SSA)与自回归综合移动平均模型(ARIMA)结合对年径流量进行预测.结果表明组合模型具有更佳的预测能力.Wang等[15]将人工神经网络模型(ANN)与集成经验模式分解(EEMD)结合用于中长期径流时间序列预测,其结果较单一ANN模型有了明显的改进.Shamseldin等[16]运用简单平均法(SAM)、加权平均法(WAM)、神经网络方法(NNM)对5个水文模型进行组合用于日径流量预测,结果表明三组组合模型的预测精度均高于单一模型.以上方法均基于确定性的理论,集成不同模型的预测结果,能够提供更精确的综合预测结果,但无法定量评价模型结构的不确定性[12].基于贝叶斯理论发展起来的贝叶斯模型平均方法(Bayesian Model Averaging,BMA)通过计算单一模型的后验概率,并基于后验概率对组合模型成员进行加权平均,判断成员模型优劣.因此,BMA可以有效处理组合模型成员的不确定性,在提供精度更高的预测结果的同时,还能提供可靠的预测概率,定量评价模型结构不确定性对预测结果的影响[17].近年来,BMA方法也被应用于水文学领域,董磊华等[18]运用BMA方法综合SIMHYD、SMAR(Soil Moisture Accounting and Routing),以及新安江模型的预报结果,推求出可靠的预报值的概率分布;Jiang等[19]利用BMA方法集成多卫星降水产品,对湘江日径流进行模拟;Xu等[20]以中国为研究区,研究了BMA在多模态水文预报后处理中的应用.以上研究均表明BMA能够提高水文预测的准确性与可靠性,还能得到更为优良的预测区间.然而,目前运用BMA方法进行中长期日径流预测的相关研究尚不多见. ...
Improving forecasting accuracy of medium and long-term runoff using artificial neural network based on EEMD decomposition
1
2015
... 针对径流预测研究通常采用单一方法进行建模与预测,难以有效利用各预测模型优势的问题,有学者提出多模型融合的方法,即将多个单一模型进行组合,通过降低单一模型的偏差,发挥各模型的优势,使预测值更加接近于实测值,进而提高径流预测结果的精确度与可靠性[13].Zhang等[14]运用奇异谱分析(SSA)与自回归综合移动平均模型(ARIMA)结合对年径流量进行预测.结果表明组合模型具有更佳的预测能力.Wang等[15]将人工神经网络模型(ANN)与集成经验模式分解(EEMD)结合用于中长期径流时间序列预测,其结果较单一ANN模型有了明显的改进.Shamseldin等[16]运用简单平均法(SAM)、加权平均法(WAM)、神经网络方法(NNM)对5个水文模型进行组合用于日径流量预测,结果表明三组组合模型的预测精度均高于单一模型.以上方法均基于确定性的理论,集成不同模型的预测结果,能够提供更精确的综合预测结果,但无法定量评价模型结构的不确定性[12].基于贝叶斯理论发展起来的贝叶斯模型平均方法(Bayesian Model Averaging,BMA)通过计算单一模型的后验概率,并基于后验概率对组合模型成员进行加权平均,判断成员模型优劣.因此,BMA可以有效处理组合模型成员的不确定性,在提供精度更高的预测结果的同时,还能提供可靠的预测概率,定量评价模型结构不确定性对预测结果的影响[17].近年来,BMA方法也被应用于水文学领域,董磊华等[18]运用BMA方法综合SIMHYD、SMAR(Soil Moisture Accounting and Routing),以及新安江模型的预报结果,推求出可靠的预报值的概率分布;Jiang等[19]利用BMA方法集成多卫星降水产品,对湘江日径流进行模拟;Xu等[20]以中国为研究区,研究了BMA在多模态水文预报后处理中的应用.以上研究均表明BMA能够提高水文预测的准确性与可靠性,还能得到更为优良的预测区间.然而,目前运用BMA方法进行中长期日径流预测的相关研究尚不多见. ...
Methods for combining the outputs of different rainfall-runoff models
1
1997
... 针对径流预测研究通常采用单一方法进行建模与预测,难以有效利用各预测模型优势的问题,有学者提出多模型融合的方法,即将多个单一模型进行组合,通过降低单一模型的偏差,发挥各模型的优势,使预测值更加接近于实测值,进而提高径流预测结果的精确度与可靠性[13].Zhang等[14]运用奇异谱分析(SSA)与自回归综合移动平均模型(ARIMA)结合对年径流量进行预测.结果表明组合模型具有更佳的预测能力.Wang等[15]将人工神经网络模型(ANN)与集成经验模式分解(EEMD)结合用于中长期径流时间序列预测,其结果较单一ANN模型有了明显的改进.Shamseldin等[16]运用简单平均法(SAM)、加权平均法(WAM)、神经网络方法(NNM)对5个水文模型进行组合用于日径流量预测,结果表明三组组合模型的预测精度均高于单一模型.以上方法均基于确定性的理论,集成不同模型的预测结果,能够提供更精确的综合预测结果,但无法定量评价模型结构的不确定性[12].基于贝叶斯理论发展起来的贝叶斯模型平均方法(Bayesian Model Averaging,BMA)通过计算单一模型的后验概率,并基于后验概率对组合模型成员进行加权平均,判断成员模型优劣.因此,BMA可以有效处理组合模型成员的不确定性,在提供精度更高的预测结果的同时,还能提供可靠的预测概率,定量评价模型结构不确定性对预测结果的影响[17].近年来,BMA方法也被应用于水文学领域,董磊华等[18]运用BMA方法综合SIMHYD、SMAR(Soil Moisture Accounting and Routing),以及新安江模型的预报结果,推求出可靠的预报值的概率分布;Jiang等[19]利用BMA方法集成多卫星降水产品,对湘江日径流进行模拟;Xu等[20]以中国为研究区,研究了BMA在多模态水文预报后处理中的应用.以上研究均表明BMA能够提高水文预测的准确性与可靠性,还能得到更为优良的预测区间.然而,目前运用BMA方法进行中长期日径流预测的相关研究尚不多见. ...
Stand volume growth model of Chinese fir plantations based on Bayesian model averaging approach
1
2021
... 针对径流预测研究通常采用单一方法进行建模与预测,难以有效利用各预测模型优势的问题,有学者提出多模型融合的方法,即将多个单一模型进行组合,通过降低单一模型的偏差,发挥各模型的优势,使预测值更加接近于实测值,进而提高径流预测结果的精确度与可靠性[13].Zhang等[14]运用奇异谱分析(SSA)与自回归综合移动平均模型(ARIMA)结合对年径流量进行预测.结果表明组合模型具有更佳的预测能力.Wang等[15]将人工神经网络模型(ANN)与集成经验模式分解(EEMD)结合用于中长期径流时间序列预测,其结果较单一ANN模型有了明显的改进.Shamseldin等[16]运用简单平均法(SAM)、加权平均法(WAM)、神经网络方法(NNM)对5个水文模型进行组合用于日径流量预测,结果表明三组组合模型的预测精度均高于单一模型.以上方法均基于确定性的理论,集成不同模型的预测结果,能够提供更精确的综合预测结果,但无法定量评价模型结构的不确定性[12].基于贝叶斯理论发展起来的贝叶斯模型平均方法(Bayesian Model Averaging,BMA)通过计算单一模型的后验概率,并基于后验概率对组合模型成员进行加权平均,判断成员模型优劣.因此,BMA可以有效处理组合模型成员的不确定性,在提供精度更高的预测结果的同时,还能提供可靠的预测概率,定量评价模型结构不确定性对预测结果的影响[17].近年来,BMA方法也被应用于水文学领域,董磊华等[18]运用BMA方法综合SIMHYD、SMAR(Soil Moisture Accounting and Routing),以及新安江模型的预报结果,推求出可靠的预报值的概率分布;Jiang等[19]利用BMA方法集成多卫星降水产品,对湘江日径流进行模拟;Xu等[20]以中国为研究区,研究了BMA在多模态水文预报后处理中的应用.以上研究均表明BMA能够提高水文预测的准确性与可靠性,还能得到更为优良的预测区间.然而,目前运用BMA方法进行中长期日径流预测的相关研究尚不多见. ...
基于贝叶斯模型平均法构建杉木林分蓄积量生长模型
1
2021
... 针对径流预测研究通常采用单一方法进行建模与预测,难以有效利用各预测模型优势的问题,有学者提出多模型融合的方法,即将多个单一模型进行组合,通过降低单一模型的偏差,发挥各模型的优势,使预测值更加接近于实测值,进而提高径流预测结果的精确度与可靠性[13].Zhang等[14]运用奇异谱分析(SSA)与自回归综合移动平均模型(ARIMA)结合对年径流量进行预测.结果表明组合模型具有更佳的预测能力.Wang等[15]将人工神经网络模型(ANN)与集成经验模式分解(EEMD)结合用于中长期径流时间序列预测,其结果较单一ANN模型有了明显的改进.Shamseldin等[16]运用简单平均法(SAM)、加权平均法(WAM)、神经网络方法(NNM)对5个水文模型进行组合用于日径流量预测,结果表明三组组合模型的预测精度均高于单一模型.以上方法均基于确定性的理论,集成不同模型的预测结果,能够提供更精确的综合预测结果,但无法定量评价模型结构的不确定性[12].基于贝叶斯理论发展起来的贝叶斯模型平均方法(Bayesian Model Averaging,BMA)通过计算单一模型的后验概率,并基于后验概率对组合模型成员进行加权平均,判断成员模型优劣.因此,BMA可以有效处理组合模型成员的不确定性,在提供精度更高的预测结果的同时,还能提供可靠的预测概率,定量评价模型结构不确定性对预测结果的影响[17].近年来,BMA方法也被应用于水文学领域,董磊华等[18]运用BMA方法综合SIMHYD、SMAR(Soil Moisture Accounting and Routing),以及新安江模型的预报结果,推求出可靠的预报值的概率分布;Jiang等[19]利用BMA方法集成多卫星降水产品,对湘江日径流进行模拟;Xu等[20]以中国为研究区,研究了BMA在多模态水文预报后处理中的应用.以上研究均表明BMA能够提高水文预测的准确性与可靠性,还能得到更为优良的预测区间.然而,目前运用BMA方法进行中长期日径流预测的相关研究尚不多见. ...
Uncertainty analysis of hydrological modeling using the Bayesian Model Averaging Method
2
2011
... 针对径流预测研究通常采用单一方法进行建模与预测,难以有效利用各预测模型优势的问题,有学者提出多模型融合的方法,即将多个单一模型进行组合,通过降低单一模型的偏差,发挥各模型的优势,使预测值更加接近于实测值,进而提高径流预测结果的精确度与可靠性[13].Zhang等[14]运用奇异谱分析(SSA)与自回归综合移动平均模型(ARIMA)结合对年径流量进行预测.结果表明组合模型具有更佳的预测能力.Wang等[15]将人工神经网络模型(ANN)与集成经验模式分解(EEMD)结合用于中长期径流时间序列预测,其结果较单一ANN模型有了明显的改进.Shamseldin等[16]运用简单平均法(SAM)、加权平均法(WAM)、神经网络方法(NNM)对5个水文模型进行组合用于日径流量预测,结果表明三组组合模型的预测精度均高于单一模型.以上方法均基于确定性的理论,集成不同模型的预测结果,能够提供更精确的综合预测结果,但无法定量评价模型结构的不确定性[12].基于贝叶斯理论发展起来的贝叶斯模型平均方法(Bayesian Model Averaging,BMA)通过计算单一模型的后验概率,并基于后验概率对组合模型成员进行加权平均,判断成员模型优劣.因此,BMA可以有效处理组合模型成员的不确定性,在提供精度更高的预测结果的同时,还能提供可靠的预测概率,定量评价模型结构不确定性对预测结果的影响[17].近年来,BMA方法也被应用于水文学领域,董磊华等[18]运用BMA方法综合SIMHYD、SMAR(Soil Moisture Accounting and Routing),以及新安江模型的预报结果,推求出可靠的预报值的概率分布;Jiang等[19]利用BMA方法集成多卫星降水产品,对湘江日径流进行模拟;Xu等[20]以中国为研究区,研究了BMA在多模态水文预报后处理中的应用.以上研究均表明BMA能够提高水文预测的准确性与可靠性,还能得到更为优良的预测区间.然而,目前运用BMA方法进行中长期日径流预测的相关研究尚不多见. ...
... 针对径流预测研究通常采用单一方法进行建模与预测,难以有效利用各预测模型优势的问题,有学者提出多模型融合的方法,即将多个单一模型进行组合,通过降低单一模型的偏差,发挥各模型的优势,使预测值更加接近于实测值,进而提高径流预测结果的精确度与可靠性[13].Zhang等[14]运用奇异谱分析(SSA)与自回归综合移动平均模型(ARIMA)结合对年径流量进行预测.结果表明组合模型具有更佳的预测能力.Wang等[15]将人工神经网络模型(ANN)与集成经验模式分解(EEMD)结合用于中长期径流时间序列预测,其结果较单一ANN模型有了明显的改进.Shamseldin等[16]运用简单平均法(SAM)、加权平均法(WAM)、神经网络方法(NNM)对5个水文模型进行组合用于日径流量预测,结果表明三组组合模型的预测精度均高于单一模型.以上方法均基于确定性的理论,集成不同模型的预测结果,能够提供更精确的综合预测结果,但无法定量评价模型结构的不确定性[12].基于贝叶斯理论发展起来的贝叶斯模型平均方法(Bayesian Model Averaging,BMA)通过计算单一模型的后验概率,并基于后验概率对组合模型成员进行加权平均,判断成员模型优劣.因此,BMA可以有效处理组合模型成员的不确定性,在提供精度更高的预测结果的同时,还能提供可靠的预测概率,定量评价模型结构不确定性对预测结果的影响[17].近年来,BMA方法也被应用于水文学领域,董磊华等[18]运用BMA方法综合SIMHYD、SMAR(Soil Moisture Accounting and Routing),以及新安江模型的预报结果,推求出可靠的预报值的概率分布;Jiang等[19]利用BMA方法集成多卫星降水产品,对湘江日径流进行模拟;Xu等[20]以中国为研究区,研究了BMA在多模态水文预报后处理中的应用.以上研究均表明BMA能够提高水文预测的准确性与可靠性,还能得到更为优良的预测区间.然而,目前运用BMA方法进行中长期日径流预测的相关研究尚不多见. ...
Comprehensive evaluation of multi-satellite precipitation products with a dense rain gauge network and optimally merging their simulated hydrological flows using the Bayesian model averaging method
1
2012
... 针对径流预测研究通常采用单一方法进行建模与预测,难以有效利用各预测模型优势的问题,有学者提出多模型融合的方法,即将多个单一模型进行组合,通过降低单一模型的偏差,发挥各模型的优势,使预测值更加接近于实测值,进而提高径流预测结果的精确度与可靠性[13].Zhang等[14]运用奇异谱分析(SSA)与自回归综合移动平均模型(ARIMA)结合对年径流量进行预测.结果表明组合模型具有更佳的预测能力.Wang等[15]将人工神经网络模型(ANN)与集成经验模式分解(EEMD)结合用于中长期径流时间序列预测,其结果较单一ANN模型有了明显的改进.Shamseldin等[16]运用简单平均法(SAM)、加权平均法(WAM)、神经网络方法(NNM)对5个水文模型进行组合用于日径流量预测,结果表明三组组合模型的预测精度均高于单一模型.以上方法均基于确定性的理论,集成不同模型的预测结果,能够提供更精确的综合预测结果,但无法定量评价模型结构的不确定性[12].基于贝叶斯理论发展起来的贝叶斯模型平均方法(Bayesian Model Averaging,BMA)通过计算单一模型的后验概率,并基于后验概率对组合模型成员进行加权平均,判断成员模型优劣.因此,BMA可以有效处理组合模型成员的不确定性,在提供精度更高的预测结果的同时,还能提供可靠的预测概率,定量评价模型结构不确定性对预测结果的影响[17].近年来,BMA方法也被应用于水文学领域,董磊华等[18]运用BMA方法综合SIMHYD、SMAR(Soil Moisture Accounting and Routing),以及新安江模型的预报结果,推求出可靠的预报值的概率分布;Jiang等[19]利用BMA方法集成多卫星降水产品,对湘江日径流进行模拟;Xu等[20]以中国为研究区,研究了BMA在多模态水文预报后处理中的应用.以上研究均表明BMA能够提高水文预测的准确性与可靠性,还能得到更为优良的预测区间.然而,目前运用BMA方法进行中长期日径流预测的相关研究尚不多见. ...
Hydrological post-processing of streamflow forecasts issued from multimodel ensemble prediction systems
1
2019
... 针对径流预测研究通常采用单一方法进行建模与预测,难以有效利用各预测模型优势的问题,有学者提出多模型融合的方法,即将多个单一模型进行组合,通过降低单一模型的偏差,发挥各模型的优势,使预测值更加接近于实测值,进而提高径流预测结果的精确度与可靠性[13].Zhang等[14]运用奇异谱分析(SSA)与自回归综合移动平均模型(ARIMA)结合对年径流量进行预测.结果表明组合模型具有更佳的预测能力.Wang等[15]将人工神经网络模型(ANN)与集成经验模式分解(EEMD)结合用于中长期径流时间序列预测,其结果较单一ANN模型有了明显的改进.Shamseldin等[16]运用简单平均法(SAM)、加权平均法(WAM)、神经网络方法(NNM)对5个水文模型进行组合用于日径流量预测,结果表明三组组合模型的预测精度均高于单一模型.以上方法均基于确定性的理论,集成不同模型的预测结果,能够提供更精确的综合预测结果,但无法定量评价模型结构的不确定性[12].基于贝叶斯理论发展起来的贝叶斯模型平均方法(Bayesian Model Averaging,BMA)通过计算单一模型的后验概率,并基于后验概率对组合模型成员进行加权平均,判断成员模型优劣.因此,BMA可以有效处理组合模型成员的不确定性,在提供精度更高的预测结果的同时,还能提供可靠的预测概率,定量评价模型结构不确定性对预测结果的影响[17].近年来,BMA方法也被应用于水文学领域,董磊华等[18]运用BMA方法综合SIMHYD、SMAR(Soil Moisture Accounting and Routing),以及新安江模型的预报结果,推求出可靠的预报值的概率分布;Jiang等[19]利用BMA方法集成多卫星降水产品,对湘江日径流进行模拟;Xu等[20]以中国为研究区,研究了BMA在多模态水文预报后处理中的应用.以上研究均表明BMA能够提高水文预测的准确性与可靠性,还能得到更为优良的预测区间.然而,目前运用BMA方法进行中长期日径流预测的相关研究尚不多见. ...
Study on climate change in mountainous region of Shulehe River Basin in past 50 years and its effect to mountainous runoff
Variation of water cycle factors in the western Qilian Mountain area under climate warming:taking the mountain watershed of the main stream of Shule River Basin for example


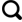



 甘公网安备 62010202000676号
甘公网安备 62010202000676号
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}